- Обучение машинного обучения на данных о производительности: полное руководство для начинающих и профессионалов
- Почему важно использовать данные о производительности для обучения ML?
- Что такое данные о производительности? Определение и виды
- Основные виды данных о производительности:
- Этапы подготовки данных о производительности для обучения ML
- Основные шаги:
- Методы и алгоритмы машинного обучения для анализа данных о производительности
- Классические алгоритмы:
- Современные методы:
- Таблица сравнения методов:
- Обучение модели на данных о производительности: практические советы
- Ключевые моменты в процессе обучения:
- Практические кейсы и примеры использования обучения ML на данных о производительности
- Кейс 1: Производственный цех
- Кейс 2: HR и управление персоналом
- Кейс 3: Аналитика финансовых показателей
Обучение машинного обучения на данных о производительности: полное руководство для начинающих и профессионалов
В современном мире, где технологии развиваются с невероятной скоростью, машиное обучение становится неотъемлемой частью многих сферы̆ человеческой деятельности․ Особенно важной его составляющей становится работа с данными о производительности — будь то показатели сотрудников, эффективность оборудования или показатели работы бизнес-процессов․ В этой статье мы расскажем о том, как правильно использовать данные о производительности для обучения моделей машинного обучения, чтобы добиться лучших результатов, автоматизировать принятие решений и повысить эффективность бизнеса․
Почему важно использовать данные о производительности для обучения ML?
Данные о производительности — это база, на которой строятся многие модели предсказания и автоматизации в различных отраслях․ Они позволяют не просто понять текущие тенденции, но и спрогнозировать будущее развитие событий, выявить слабые места и найти возможности для оптимизации․
Например, в производственной сфере такие данные помогают предсказать возможные поломки оборудования, тем самым минимизируя время простоя и связанные с этим потери․ В сфере HR и управления персоналом — позволяют определить ключевые показатели эффективности работников, выявить лучших сотрудников и понять, какие факторы влияют на продуктивность․
Обучая модель на таких данных, мы можем автоматизировать анализ и принятие решений, что существенно ускоряет бизнес-процессы и делает их более точными и объективными․
Что такое данные о производительности? Определение и виды
Данные о производительности — это информация, которая фиксирует эффективность выполнения определенных задач или процессов․ Они могут варьировать в зависимости от сферы деятельности и конкретных целей․
Основные виды данных о производительности:
- Данные о работе сотрудников: количество выполненных задач, время на задачу, качество работы, уровень удовлетворенности клиента․
- Данные о доходности: показатели продаж, доходы, затраты․
- Данные о производственном оборудовании: время работы оборудования, степень его загрузки, частота поломок․
- Финансовые показатели процесса: скорость выполнения заказа, уровень ошибок, время выполнения этапов․
Эти данные могут собираться различными методами: автоматическими системами учета, опросами, логами системы, IoT-датчиками и другими источниками․
| Вид данных | Источник | Особенности | Преимущества | Кейс использования |
|---|---|---|---|---|
| Данные сотрудников | CRM, системы учета времени | Подробная информация о выполненных задачах | Обучение моделей предсказания эффективности | Оптимизация распределения задач |
| Данные оборудования | IoT-датчики, лог системы | Реальное время работы техники | Прогнозирование поломок | Планирование профилактических ремонтов |
| Финансовые показатели | Бухгалтерия, ERP-системы | Объем доходов и затрат | Анализ прибыльности | Определение прибыльных продуктов |
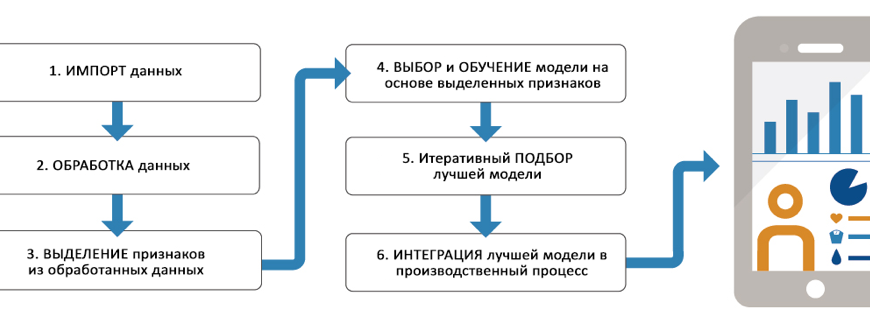
Этапы подготовки данных о производительности для обучения ML
Перед тем, как перейти к обучению модели машинного обучения, необходимо правильно подготовить исходные данные․ Этот этап критически важен для получения релевантных и точных результатов․
Основные шаги:
- Сбор данных: выбор источников и автоматизация процесса получения информации․
- Очистка данных: удаление ошибок, устранение дублей, обработка пропусков․
- Анализ и визуализация: поиск закономерностей, выявление выбросов и аномалий․
- Трансформация данных: нормализация, кодирование категориальных переменных, создание новых признаков․
- Разделение данных: распределение на обучающую, тестовую и валидационную выборки․
Эти шаги требуют тщательного подхода, так как от качества подготовленных данных зависит точность всех последующих моделей․
Методы и алгоритмы машинного обучения для анализа данных о производительности
На сегодняшний день существует обширный арсенал методов и алгоритмов, предназначенных для анализа и прогнозирования на базе данных о производительности․ Каждый из них подходит для решения определенных задач — от простых регрессий до сложных нейронных сетей․
Классические алгоритмы:
- Линейная регрессия: прогнозирование продолжительности задач или доходов․
- Логистическая регрессия: классификация сотрудников по уровню эффективности․
- Деревья решений и случайный лес: выявление факторов, влияющих на производительность․
- SVM (поддерживающие векторные машины): классификация и регрессия для сложных задач․
Современные методы:
- Глубокое обучение: нейронные сети для анализа больших объемов данных, например, видео с датчиков․
- Методы ансамблирования: объединение нескольких моделей для повышения точности․
Таблица сравнения методов:
| Метод | Тип задачи | Плюсы | Минусы | Примеры использования |
|---|---|---|---|---|
| Линейная регрессия | Регрессия | Простота, интерпретируемость | Работает при линейных связях | Прогноз времени выполнения задач |
| Деревья решений | Классификация и регрессия | Интерпретируемость, немного настроек | Могут переобучаться | Выявление факторов эффективности |
| Нейронные сети | Различные (классификация, регрессия) | Обработка больших данных | Требуют высокой вычислительной мощности | Анализ видео и сенсорных данных |
Обучение модели на данных о производительности: практические советы
Обучение модели — это не только выбор алгоритма и настройка гиперпараметров․ Важно учитывать множество факторов, чтобы результат был качественным и надежным․
Ключевые моменты в процессе обучения:
- Балансировка данных: избегайте дисбаланса классов, чтобы избежать искажения результатов․
- Выбор признаков: использование релевантных переменных, создание новых признаков для повышения точности․
- Кросс-валидация: проверка устойчивости модели на различных подвыборках․
- Тюнинг гиперпараметров: автоматизация поиска оптимальных настроек модели․
- Оценка качества: использование метрик, таких как точность, F1-score, средняя квадратичная ошибка․
Постоянное тестирование и улучшение модели — залог достижения стабильных результатов․
Практические кейсы и примеры использования обучения ML на данных о производительности
Чтобы понять, как теория реализуется на практике, рассмотрим несколько реальных кейсов․
Кейс 1: Производственный цех
Компания внедрила систему сбора данных о работе оборудования и эффективности операторов․ Обучили модель, которая прогнозирует потенциальные поломки за 7 дней до возникновения․ Это позволило снизить время простоя оборудования на 25%, а затраты на ремонт — на 15%․
Кейс 2: HR и управление персоналом
На базе данных о выполнении задач и отзывов сотрудников была обучена модель, которая предсказывает уровень эффективности новых работников․ Такой подход помог работодателю снизить уровень текучести сотрудников и повысить качество подборки персонала․
Кейс 3: Аналитика финансовых показателей
Обработка данных о продажах и доходах позволила автоматизировать прогнозирование прибыли, выявлять наиболее рентабельные направления деятельности и оптимизировать расходы․
Итак, использование данных о производительности для обучения моделей машинного обучения — это мощный инструмент улучшения бизнес-процессов, повышения эффективности и автоматизации․ Однако важнейшее, правильная подготовка данных, осознанный подбор методов и непрерывное тестирование моделей․ Помните, что успех зависит от вашей внимательности и желания постоянно совершенствоваться․
Если вы только начинаете свой путь в области машинного обучения, не бойтесь экспериментировать с разными алгоритмами, анализируйте результаты и учитесь на ошибках․ Главное — поставьте себе ясные цели и двигайтесь к ним с настойчивостью и любознательностью․
Вопрос: Какие основные сложности могут возникнуть при использовании данных о производительности для обучения моделей ML?
Основные сложности связаны с качеством и полнотой данных․ Иногда данные бывают неполными, содержат ошибки или дублируются․ Также существует риск искажения результатов из-за несбалансированных выборок или наличия выбросов․ Еще одна проблема — неподготовленность данных, необходимость их масштабирования и кодирования․ Все эти факторы требуют терпения и аккуратности на этапе подготовки․
Подробнее
| ИСИ 1 | ИСИ 2 | ИСИ 3 | ИСИ 4 | ИСИ 5 |
|---|---|---|---|---|
| машинное обучение на производственных данных | анализ производительности сотрудников | предсказание поломок оборудования | подготовка данных для ML | использование ИИ для бизнес-аналитики |
| методы обучения на производственных данных | модели прогнозирования эффективности | обработка пропусков в данных | регрессия и классификация для бизнеса | трудности внедрения ИИ в промышленность |
| проблемы качества данных | выбросы и аномалии в данных | подготовка данных для обучения моделей | поиск релевантных признаков | стратегии повышения точности модели |