
- ML в запасах: Как правильно прогнозировать оборачиваемость для повышения эффективности складского управления
- Что такое оборачиваемость запасов и почему она важна?
- Почему важно правильно прогнозировать оборачиваемость?
- Как работает машинное обучение при прогнозировании оборачиваемости?
- Плюсы использования ML для прогнозирования оборачиваемости
- Как построить модель прогнозирования оборачиваемости
- Шаги по созданию модели
- Кейс: использование ML для оптимизации запасов в реальной компании
- Практические рекомендации по внедрению ML в управление запасами
ML в запасах: Как правильно прогнозировать оборачиваемость для повышения эффективности складского управления
В современном мире бизнесы сталкиваются с беспрецедентным ростом объемов данных и увеличением требований к эффективности управления запасами. Одним из ключевых инструментов для достижения этой цели является использование машинного обучения (ML) в процессе прогнозирования оборачиваемости запасов. В этой статье мы подробно расскажем, что такое оборачиваемость запасов, почему её важно учитывать, а также как современные технологии помогают делать точные прогнозы, позволяющие снизить издержки и повысить прибыльность компании.
Что такое оборачиваемость запасов и почему она важна?
Оборачиваемость запасов — это ключевой показатель, который показывает, как быстро товары на складе продаются или обновляются за определённый период времени. Он помогает понять эффективность управления запасами, а также своевременность пополнения и сокращение излишков. Чем выше оборачиваемость, тем быстрее товары уходят, что снижает издержки на хранение и уменьшает риск устаревания продукции.
Если говорить проще, то высокая оборачиваемость свидетельствует о том, что товары реализуются быстро, а бизнес работает более эффективно. Наоборот, низкая оборачиваемость говорит о возможно излишних запасах, что ведет к дополнительным затратам и уменьшению ликвидности бизнеса.
Почему важно правильно прогнозировать оборачиваемость?
Точная оценка оборачиваемости позволяет принимать правильные управленческие решения, такие как:
- Оптимизация уровня запасов, избегая как излишек, так и дефицит товара;
- Планирование закупок и пополнения склада;
- Повышение оборотности и, следовательно, рентабельности бизнеса;
- Минимизация затрат на хранение и логистику.
Именно поэтому современные методы прогнозирования, особенно машинное обучение, становятся незаменимыми инструментами в арсенале логистов и менеджеров по запасам.
Как работает машинное обучение при прогнозировании оборачиваемости?
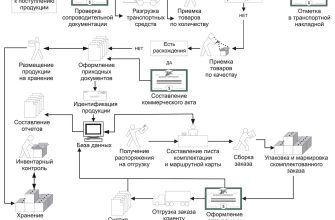
Машинное обучение позволяет создавать модели, которые на основе большого объема исторических данных могут предугадывать будущую оборачиваемость запасов с высокой точностью. В отличие от традиционных методов прогнозирования (например, скользящих средних или линейной регрессии), ML учитывает сложные взаимосвязи между множеством факторов и способен адаптироваться к изменяющимся условиям рынка.
Процесс применения ML в прогнозировании включает несколько этапов:
- Сбор данных: исторические показатели продаж, сезонность, акции, экономические факторы, данные о поставщиках и логистике.
- Подготовка данных: очистка, нормализация и выделение признаков.
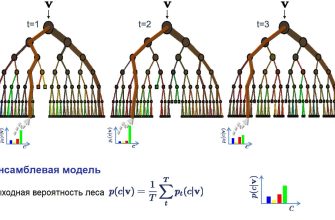
- Обучение модели: применение алгоритмов машинного обучения, таких как случайные леса, градиентный бустинг или нейронные сети.
- Валидация и тестирование: проверка точности модели на новых данных.
- Развертывание и использование: интеграция модели в бизнес-процессы для ежедневного прогнозирования.
Плюсы использования ML для прогнозирования оборачиваемости
| Преимущество | Описание |
|---|---|
| Точность | Модели машинного обучения учитывают множество факторов и выявляют сложные взаимосвязи, что повышает точность прогнозов. |
| Адаптивность | Модели могут самостоятельно обучаться на новых данных, что позволяет быстро реагировать на изменения рынка. |
| Масштабируемость | Обработка больших объемов данных позволяет строить более точные прогнозы в крупных бизнес-системах. |
| Автоматизация | Позволяет снизить человеческий фактор и автоматизировать процесс планирования запасов. |
| Экономия ресурсов | Оптимизация запасов приводит к снижению издержек на хранение и логистику. |
Как построить модель прогнозирования оборачиваемости
Создание эффективной модели прогнозирования — это не только выбор подходящего алгоритма, но и правильная подготовка данных, а также настройка параметров модели. Ниже приведены основные шаги:
Шаги по созданию модели
- Анализ данных: Собрать максимально полные данные — продажи, сезонность, промоакции, экономические показатели, логистика и др.
- Обработка данных: Удаление пропущенных значений, аномалий, нормализация признаков.
- Выбор моделей: Исследование различных алгоритмов машинного обучения, таких как регрессия, деревья решений, градиентный бустинг и нейронные сети.
- Обучение моделей: Разделение данных на обучающую и тестовую выборки, обучение и настройка гиперпараметров.
- Тестирование: Проверка точности модели и выявление её слабых мест.
- Внедрение: Интеграция модели в бизнес-системы и постоянный мониторинг результатов.
Результатом становится инструмент, который точно прогнозирует сроки и объемы реализации запасов, помогая минимизировать затраты и оптимизировать работу склада.
Кейс: использование ML для оптимизации запасов в реальной компании
Для закрепления представленной теории рассмотрим пример, как одна крупная розничная сеть внедрила систему машинного обучения для прогнозирования оборачиваемости товаров на складах. До внедрения системы бизнес сталкивался с избыточными запасами сезонных товаров, что приводило к значительным издержкам на хранение и утере части товаров из-за устаревания.
После внедрения модели, основанной на градиентном бустинге, компания смогла:
- Автоматически прогнозировать спрос по различным категориям товаров на основе сезонности, акций и внешних факторов.
- Оптимально планировать закупки, сокращая излишки и избегая дефицита.
- Снизить затраты на складирование на 20% уже в первые полгода использования системы.
Этот пример показывает, насколько важное значение имеет использование современных технологий для повышения рентабельности и конкурентоспособности компании.
Практические рекомендации по внедрению ML в управление запасами
Чтобы успешно интегрировать машинное обучение в бизнес-процессы, необходимо следовать нескольким важным принципам:
- Подготовить инфраструктуру: обеспечить сбор, хранение и обработку данных в автоматическом режиме.
- Обучить команду: сотрудники должны разбираться в основах машинного обучения и понимать принципы работы моделей.
- Постоянный мониторинг: следить за точностью и актуальностью моделей, обновлять их по мере необходимости.
- Интеграция с бизнес-процессами: автоматизация прогноза должна быть связана с системами ERP, WMS и управленческими решениями.
- Постоянное обучение системы: регулярное обучение моделей на новых данных для повышения точности прогнозов.
Использование машинного обучения в прогнозировании оборачиваемости запасов — это революционный подход, который помогает бизнесам стать более гибкими, снизить затраты и повысить эффективность. В условиях постоянных изменений рыночной ситуации именно современные технологии позволяют быстро адаптироваться, принимать обоснованные решения и быть на шаг впереди конкурентов.
Если вы еще не начали внедрять ML в управление запасами, сейчас самое время разобраться, как это сделать на практике и начать получать максимальную отдачу уже сегодня.
Что самое важное при использовании машинного обучения для прогнозирования запасов?
Самое важное, правильно подготовить и структурировать данные, а также обеспечить постоянное обновление и мониторинг моделей. Только в этом случае можно добиться высокой точности прогнозов и реалистичных бизнес-решений, основанных на данных, а не на догадках.
Подробнее
| прогнозирование запасов | машинное обучение в логистике | оптимизация складских запасов | анализ продаж с помощью ML | автоматизация управления запасами |
| предиктивная аналитика для запасов | нейронные сети в логистике | сезонное планирование запасов | дары спроса для бизнеса | Data Science в управлении складом |
| большие данные для логистики | методы машинного обучения | предсказание спроса | оптимизация закупок ML | эффективное управление запасами |
| технологии биг дата | прогноз продаж для бизнеса | анализ данных в логистике | AI и автоматизация склада | поддержка решений с помощью ML |
| управление запасами с AI | цифровая трансформация логистики | стратегии прогнозирования спроса | инновационные подходы в складском деле | умные системы учета товаров |