- Кластеризация: Надежность — ключевые аспекты и практическое применение
- Что такое кластеризация и зачем она нужна?
- Основные методы кластеризации и их особенности
- Что влияет на надежность кластеризации?
- Практические советы для повышения надежности кластеризации
- Обзор современных инструментов и программных решений
- Вопрос к статье:
Кластеризация: Надежность — ключевые аспекты и практическое применение
В современном мире, где объем данных растет с каждым днем, умение правильно группировать и структурировать информацию становится неотъемлемой частью успеха в различных сферах — от анализа рынка до машинного обучения. Кластеризация — это один из основных методов, позволяющих определить, какие объекты или данные можно объединить в логические группы без предварительных знаний о них. Однако, важнейшим аспектом её эффективности является надежность — насколько результаты соответствуют реальности и не являются случайными или ошибочными.
Статья посвящена именно этой теме — как оценить и повысить надежность кластеризации, с какими трудностями можно столкнуться и каким образом добиться оптимальной точности группировки. Поделимся практическими советами и разберем примеры из реальной жизни и современных технологий.
Что такое кластеризация и зачем она нужна?
Кластеризация — это процесс распознавания структур внутри данных, при котором схожие объекты объединяются в группы, называемые кластер или кластеры. Это важная задача в области анализа данных, так как она помогает найти закономерности, сокрытые в большом массиве информации, и структурировать данные для дальнейшего использования.
Например, в маркетинге кластеризация помогает сегментировать клиентов по их покупательскому поведению, предпочтениям и демографическим характеристикам. В машинном обучении — она служит этапом для разделения обучающей выборки на группы, что позволяет улучшить качество распознавания и предсказаний.
Ключевое преимущество данной методики — возможность работать без предварительного знания о структуре данных, что делает её универсальной и мощной. Однако, именно надежность результатов часто становится точкой отсчета для оценки эффективности выбранных алгоритмов.
Основные методы кластеризации и их особенности
На сегодняшний день существует множество методов кластеризации, каждый из которых имеет свои плюсы и минусы, а также уровень надежности в конкретных условиях. Ниже рассмотрим наиболее популярные:
- Метод k-средних (k-means): один из самых распространенных, основан на итеративном перемещении центров групп и минимизации внутрикластерных расстояний. Он прост в реализации, но чувствителен к выбору стартовых центров и особенностям данных.
- Иерархическая кластеризация: создает древовидную структуру кластеров, что позволяет анализировать данные на разных уровнях. Надежность зависит от метода расчета расстояний и критериев объединения.
- DBSCAN: критерий плотности, хорошо работает с шумами и выбросами, подходит для данных с произвольной формой кластеров. Однако параметры требуют тонкой настройки.
- Кластеризация с помощью алгоритма плотностного отделения (HDBSCAN): расширение DBSCAN, более устойчивое к параметрам, обеспечивает высокий уровень надежности для сложных данных.
| Метод | Плюсы | Минусы | Область применения | Рекомендуемый уровень надежности |
|---|---|---|---|---|
| k-средних | Простота реализации, быстрая обработка | Чувствителен к начальным условиям, сложно определить число кластеров | Обработка больших объемов данных, сегментация клиентов | Средняя |
| Иерархическая | Гибкость, возможность анализа на разных уровнях | Медлительная при больших данных | Геномика, социальные сети | Умеренная |
| DBSCAN | Работает с шумами, не требует задания числа кластеров заранее | Чувствителен к выбору радиуса и минимального количества точек | Обнаружение аномалий, географические данные | Высокая |
| HDBSCAN | Работает с разнородными данными, устойчива к параметрам | Сложнее реализовать | Обработка больших и сложных наборов данных | Высокая |
Что влияет на надежность кластеризации?
На качество и надежность результата влияет множество факторов. Среди них особое место занимают выбор алгоритма, параметры настройки, предобработка данных и качество исходных данных.
- Качество исходных данных: наличие шума, выбросов, пропущенных значений негативно сказывается на итоговых кластерах. Тщательная очистка и нормализация, обязательный этап.
- Выбор алгоритма: применение неподходящего метода к конкретным данным может привести к неправильным группировкам или высокой чувствительности к малым изменениям.
- Настройка параметров: правильный подбор радиусов, числа кластеров или других параметров значительно повышает надежность.
- Валидация результата: использование методов внутренней проверки (например, silhouette score) помогает оценить качество кластеров и их стабильность.
Чтобы повысить надежность, рекомендуются тестирования с разными настройками, использование внешних метрик и комбинирование методов.
| Фактор | Влияние | Рекомендуемые действия |
|---|---|---|
| Качество данных | Высокое влияние на точность | Очистка, нормализация, устранение выбросов |
| Выбор алгоритма | Определяющий фактор надежности | Пробное тестирование нескольких методов |
| Параметры | Могут значительно искажать результат | Настройка через кросс-валидацию или автоматические методы |
| Валидация и проверка | Обеспечивают объективную оценку | Используйте метрики, такие как silhouette, Dunn, Davies-Bouldin |
Практические советы для повышения надежности кластеризации
Чтобы добиться высокой надежности результатов, достаточно следовать ряду практических правил:
- Всегда начинайте с предварительной подготовки данных: удаляйте шумы, пропуски, применяйте масштабирование.
- Выбирайте несколько методов кластеризации: сравнивайте результаты, анализируйте стабильность полученных групп.
- Используйте внутренние метрики: такие как индекс силуэта, чтобы оценить качество кластеров.
- Проводите тестирование на различных параметрах: выбирайте те, что дают наиболее стабильные и логичные результаты.
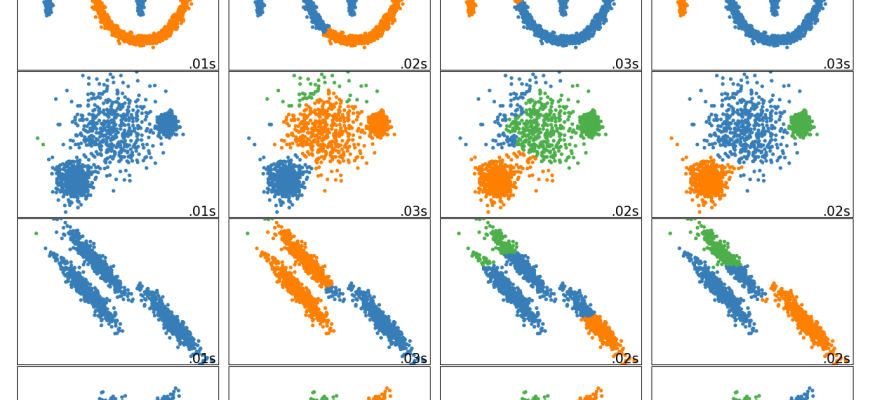
- Анализируйте результаты визуально и с использованием графиков: это помогает заметить особенности и возможные ошибки.
Практика показывает, что последовательное применение этих правил позволяет значительно повысить доверие к результатам и уверенность в их надежности.
Обзор современных инструментов и программных решений
Для реализации кластеризации широко используются как коммерческие, так и бесплатные инструменты. Важно выбрать тот, который позволяет максимально повысить надежность анализа:
- Scikit-learn: популярная библиотека для Python с широким набором алгоритмов и инструментов оценки.
- Кластеры в программе RapidMiner: удобный графический интерфейс, подходящий для новичков и профессионалов.
- Orange Data Mining: открытая платформа с богатым функционалом для анализа данных и кластеризации.
- HDPython: мощное решение для HDBSCAN и других методов плотностной кластеризации.
- Tableau и Power BI: позволяют визуализировать результаты кластеризации и оценить надежность наглядно.
Выбор инструмента зависит от конкретных задач, объема данных и уровня экспертизы пользователя, однако, правильный подбор программных средств значительно повышает шансы получить надежные, точные и интерпретируемые результаты.
Практическое использование нескольких методов, визуализация и автоматизация проверки, ключ к повышению доверия к полученным группировкам. В современном мире технологии позволяют автоматизированно оценивать и улучшать качество кластеризации, делая ее более надежной и применимой в самых различных сферах.
Ответственно относясь к этим аспектам, мы сможем максимально эффективно использовать кластеризацию для решения своих задач, не поддаваясь ошибкам и недочетам, и строить более точную и понятную картину мира вокруг нас.
Вопрос к статье:
Можно ли полностью доверять результатам кластеризации в сложных данных и как убедиться в их надежности?
Полностью доверять результатам любой кластеризации сложно, особенно когда речь идет о сложных, высокоразмерных данных или данных с большим количеством шумов и выбросов. Однако, доверие можно значительно повысить посредством систематической оценки качества кластеров. Использование внутренних метрик (например, индекс силуэта), визуализация результатов, настройка параметров и применение нескольких методов позволяют выявить и снизить ошибки. В конечном итоге, надежность определяется степенью согласованности полученных групп с реальными характеристиками данных и целями анализа. Постоянное тестирование и кросс-проверки — залог уверенности в итоговых выводах.
Подробнее
| Запрос №1 | Запрос №2 | Запрос №3 | Запрос №4 | Запрос №5 |
|---|---|---|---|---|
| лучшие алгоритмы кластеризации | методы определения надежных кластеров | примеры использования кластеризации | подготовка данных для кластеризации | метрики оценки кластеров |
| использование HDBSCAN | популярные инструменты для кластеризации | надежность результатов машинного обучения | как выбрать параметры кластеризации | оценка качества кластерных структур |
| анализ ошибок кластеризации | проблемы шумов и выбросов | примеры из бизнеса и науки | инструменты визуализации кластеров | рекомендуемые параметры для алгоритмов |