- Анализ качества данных в логистических системах для машинного обучения: секреты успеха и практические советы
- Что такое качество данных и почему оно важно для машинного обучения?
- Методы оценки качества данных в логистике
- Анализ пропущенных данных
- Проверка на согласованность и дублирование данных
- Тестирование актуальности и временной полноты данных
- Практические рекомендации по повышению качества данных для ML в логистике
- Автоматизация сбора и проверки данных
- Использование методов предобработки данных
- Обучение и развитие команды специалистов по данным
- Контроль и аудит данных
- LSI Запросы к статье
Анализ качества данных в логистических системах для машинного обучения: секреты успеха и практические советы
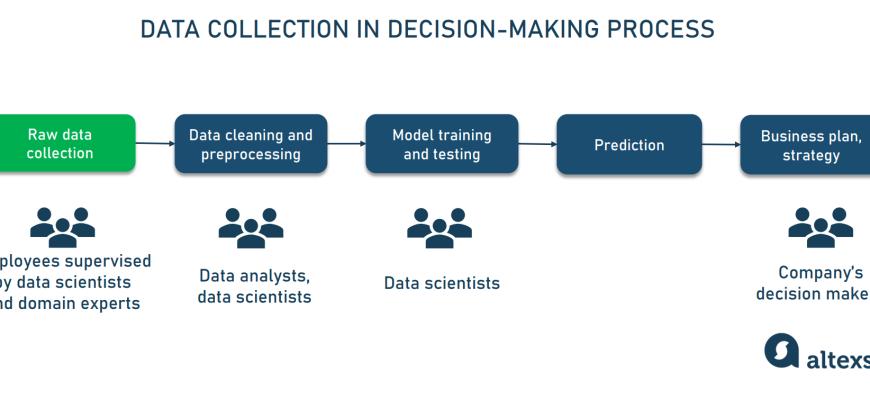
В современную эпоху цифровых технологий и стремительного развития логистики, использование методов машинного обучения (ML) становится неотъемлемой частью управления цепочками поставок, оптимизации маршрутов, прогнозирования спроса и многих других аспектов логистической деятельности․ Однако, чтобы внедрение таких решений было успешным, необходимо обеспечить высокий уровень качества данных, которые используются для обучения моделей․ Ведь именно качество исходных данных во многом определяет точность, надежность и эффективность алгоритмов․
Нередко, сталкиваясь с задачами внедрения ML в логистические системы, команды специалистов осознают, что основная проблема кроется не в сложности моделей, а в недостатке или низком качестве данных․ Поэтому анализ и улучшение качества данных является ключевым этапом, который обеспечивает стабильность и предсказуемость работы системы․ В этой статье мы расскажем о том, как правильно оценивать качество данных, какие параметры учитывать, и поделимся практическими рекомендациями для повышения эффективности ваших решений․
Что такое качество данных и почему оно важно для машинного обучения?
Качество данных — это совокупность характеристик, определяющих пригодность данных для конкретных целей, в данном случае — для обучения ML-моделей в логистике․ Важность этого параметра невозможно переоценить, поскольку недостатки данных могут привести к неправильным выводам, снижению точности прогнозов и, как следствие, к убыткам и ухудшению клиентского опыта․
Когда мы говорим о качестве данных, мы обычно рассматриваем такие параметры, как:
- Полнота — все ли необходимые данные собраны?
- Точность — соответствуют ли данные реальности?
- Согласованность — нет ли противоречий внутри данных?
- Актуальность — насколько свежие и актуальные данные?
- Наличие пропусков и шумов — отсутствуют ли недостающие или искажающие информацию элементы?
От правильной оценки этих параметров зависит выбор методов предобработки, очистки и доработки данных, а также успешность обучения моделей․ Без качественных данных даже самая продвинутая модель не сможет показать надежных результатов․
Методы оценки качества данных в логистике
Анализ пропущенных данных
Одним из первых шагов при оценке качества является проверка наличия пропущенных значений․ В логистических системах пропуски могут встречаться из-за ошибок ввода, отсутствия информации или технических сбоев․ Их обнаружение помогает понять, насколько данные полные и готовые к использованию в моделях․
| Параметр | Метод анализа | Что показывает | Пример |
|---|---|---|---|
| Процент пропусков | Подсчет пропущенных значений | Степень полноты данных | Если в 20% строк отсутствует поле "Дата доставки" |
| Анализ распределения | Гистограммы, диаграммы | Выявление аномальных или отсутствующих данных | Выявление, что 95% заказов имеют вес менее 200 кг, а некоторые — более 2 тонн |
Проверка на согласованность и дублирование данных
При сборе данных часто возникает ситуация, когда одна и та же информация сохранена в разных таблицах или файлах․ Анализ согласованности позволяет выявить такие дубли и противоречия, что помогает очистить данные и сделать их более надежными для обучения․
- Обнаружение дубликатов по ключевым полям (например, номер заказ, код склада)․
- Проверка совпадения значений в связанных таблицах․
- Использование алгоритмов кластеризации для поиска похожих записей․
Тестирование актуальности и временной полноты данных
В логистике важна своевременность данных, так как решения основаны на текущей ситуации․ Проверка временных параметров, таких как дата отправки, доставки, обновление статусов, помогает понять, насколько свежа информация․
| Параметр | Метод оценки | Значение | Критерии |
|---|---|---|---|
| Дата последнего обновления | Проверка дат | Обновлено за последние 24 часа | Данные считаются актуальными |
| Интервал между событиями | Анализ временных разрывов | Более 3 дней, риск устаревших данных | Параметр для автоматической обработки |
Практические рекомендации по повышению качества данных для ML в логистике
Автоматизация сбора и проверки данных
Одним из самых эффективных методов повышения уровня качества данных является внедрение автоматизированных систем для их сбора и проверки․ Это позволяют минимизировать человеческий фактор и снизить риск ошибок․ В рамках логистических систем можно использовать такие инструменты, как встроенные валидаторы, скрипты для автоматической очистки и проверки данных, а также системы оповещений об аномалиях․
Использование методов предобработки данных
- Заполнение пропусков с помощью статистических методов или моделей прогнозирования․
- Выделение и удаление шумов и выбросов;
- Кросс-проверка данных из разных источников для повышения точности․
Обучение и развитие команды специалистов по данным
Инвестирование в развитие компетенций сотрудников, умеющих управлять данными, аналитикой и машинным обучением, — залог высокого качества данных и успешных проектов․ Постоянное обучение, использование современных инструментов и участие в профильных конференциях позволяют оставаться в курсе последних трендов․
Контроль и аудит данных
Регулярный аудит данных помогает своевременно выявлять и устранять ошибки и противоречия․ Внедрение политик контроля качества, использование автоматизированных средств проверки и документирование процедур позволяют иметь надежную базу для обучения моделей․
Обеспечение высокого качества данных — это фундамент успешной реализации машинного обучения в логистике․ Это не разовая задача, а постоянный процесс, требующий системного подхода, автоматизации, развития команды и регулярных проверок․ Только так можно добиться надежных результатов, которые реально повлияют на эффективность систем, снизят издержки и повысят уровень сервиса․
Поддерживая качество данных на должном уровне, мы создаем прочный фундамент для новых инновационных решений, автоматизации и роста бизнеса в условиях современного динамичного рынка․ Помните: без качественной информации никакая модель не даст максимальной отдачи, а ваши решения рискуют оказаться ошибочными и дорогими․
В чем заключается ключевая задача анализа качества данных для ML в логистике, и как правильно её реализовать?
Ключевая задача — это обеспечить полноту, точность, актуальность и согласованность данных, необходимую для обучения стабильных и надежных моделей машинного обучения․ Для этого требуется систематически проводить оценку данных по описанным выше параметрам: анализ пропущенных и шумных данных, проверка согласованности, актуальности и полноты, а также внедрять процедуры автоматической очистки и контроля․ Постоянный мониторинг и развитие компетенций команды позволяют поддерживать высокий стандарт качества и достигать поставленных бизнес-целей в логистике․
LSI Запросы к статье
Подробнее
| Методы оценки качества логистических данных | Оптимизация данных для ML в логистике | Проверка свежести логистических данных | Инструменты автоматической очистки данных | Поддержка актуальности данных в логистике |
| Обучение команд по управлению данными | Анализ пропусков и шумов данных | Обеспечение согласованности данных | Методы выявления дубликатов и противоречий | Лучшие практики по контролю качества данных |
| Автоматизация процессов проверки данных | Использование моделей прогнозирования для заполнения данных | Эффективное внедрение систем мониторинга | Роль автоматизации в повышении качества данных | Развитие специалистов по работе с данными |